Исследование, опубликованное недавно в журнале Nature Machine Intelligence, было посвящено проблеме ограниченной доступности медицинских изображений с комментариями человека или маркировкой, используя состязательный подход к обучению на основе немаркированных данных.
Это исследование, проведенное инженерным факультетом Университета Монаш и факультетом информационных технологий, могло бы продвинуть область анализа медицинских изображений для радиологов и других экспертов в области здравоохранения.
Кандидат технических наук Химаши Пейрис с инженерного факультета сказал, что исследовательский проект был направлен на создание конкуренции между двумя компонентами системы искусственного интеллекта «двойного обзора».
«Одна часть системы искусственного интеллекта пытается имитировать то, как радиологи считывают медицинские изображения, помечая их, в то время как другая часть системы оценивает качество сканов с маркировкой, сгенерированных искусственным интеллектом, сравнивая их с ограниченными сканированиями с маркировкой, предоставляемыми радиологами», — сказал Пейрис.
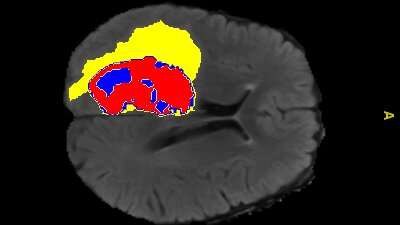
«Традиционно радиологи и другие медицинские эксперты комментируют или помечают медицинские снимки вручную, выделяя конкретные области, представляющие интерес, такие как опухоли или другие поражения. Эти ярлыки обеспечивают руководство или надзор за обучением моделей искусственного интеллекта.
«Этот метод основан на субъективной интерпретации отдельных людей, отнимает много времени и подвержен ошибкам, а также длительным периодам ожидания пациентов, обращающихся за лечением».
Доступность крупномасштабных наборов данных медицинских изображений с аннотациями часто ограничена, поскольку для аннотирования многих изображений вручную требуются значительные усилия, время и опыт.
Алгоритм, разработанный исследователями Monash, позволяет нескольким моделям искусственного интеллекта использовать уникальные преимущества помеченных и немаркированных данных и извлекать уроки из прогнозов друг друга, помогая повысить общую точность.
«В трех общедоступных наборах медицинских данных, используя 10%-ную маркировку данных, мы добились улучшения в среднем на 3% по сравнению с самым последним современным подходом при идентичных условиях», — сказал Пейрис.
«Наш алгоритм дал новаторские результаты в обучении под наблюдением, превзойдя предыдущие современные методы. Он демонстрирует замечательную производительность даже при ограниченном количестве аннотаций, в отличие от алгоритмов, которые полагаются на большие объемы аннотированных данных.
«Это позволяет моделям искусственного интеллекта принимать более обоснованные решения, подтверждать свои первоначальные оценки и выявлять более точные диагнозы и решения о лечении».
Следующий этап исследований будет сосредоточен на расширении приложения для работы с различными типами медицинских изображений и разработке специализированного комплексного продукта, который радиологи смогут использовать в своей практике.